这一年ICLR被拒,IJCAI被拒,ICDE没赶上,ICML还在赶,除了解决了显卡设备的问题以外真实毫无进展。前几天参加了阿里达摩院联邦学习组的电话面试,最后过了,估计要去实习一年了,希望能搞出一点东西,本着开源精神这里简要写一下面经。
面试流程
我只有一轮电话面试,是晚上9点打给我的,10点30结束,大概持续了1个半小时。面试分为三个环节,首先是面试官提问一些相关领域问题,在提问的时候会追问到细节。然后会问一些操作系统,计算机组成的东西,最后会出一道不难的数据结构算法题,要求当场在线写出来。我的项目是深度学习方面的,因此问了很多深度学习的细节问题。
深度学习面试问题
阐述一下你知道的神经网络结构,以及它们的异同点。
这个问题我是按时间顺序回答的。
首先AlexNet引入了多层卷积核堆叠的结构,这个结构用11*11, 5*5, 3*3的卷积核堆叠而成,预测准确率很高。
然后VGG提出了可以用多层3*3的卷积核代替更大的卷积核,比如5*5的卷积核可以用2个3*3的卷积核代替,7*7的卷积核可以用3个3*3的卷积核代替,这样可以减少参数量,同时让网络更深。同时,VGG还给出了卷积神经网络模块的基本范式,即卷积-正则化-激活(Conv-BN-ReLU)的结构,被后面所沿用。
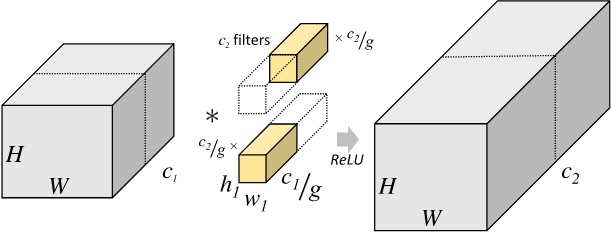
之后,Inception Net提出了Bottleneck结构,即针对卷积神经网络层数较深的时候,输入的通道变得很多,此时参数量会大大膨胀这一情况,提出了可以把3*3的卷积拆成1*1与3*3卷积的结合,第一个1*1的卷积负责进行通道整合,第二个3*3的卷积负责特征匹配。这种结构解决了深层卷积神经网络的参数膨胀问题, 例如输入通道为$c_{in}$,输出通道为$c_{out}$的情况,如果直接进行卷积,需要的参数量为$c_{in}\times 3 \times 3 \times c_{out}$,而采用Bottleneck结构,令1*1卷积将$c_{in}$通道变成$c_{middle}$通道,则使得参数变成了$c_{in}\times c_{middle}+c_{middle}\times 3 \times 3 \times c_{out}$, 当输入通道很大的时候,这种结构能够减少参数量,而且可以进行特征聚合。
基于Bottleneck结构,ResNet被提出了,它在卷积操作的同时引入了恒等映射(Identity Map)作为跳层连接,解决了深层卷积神经网络梯度消失的问题,这种做法也被扩展到Densenet使用。
我当时就回答到这里,后面是一些扩展。
之后,Shufflenet结合Bottleneck结构与分组卷积方式,提出的网络结构大大减少了参数量。分组卷积通过将输入通道为X的特征分为G组,每一组用相同的特征核,将参数量缩小了X/G倍。
Shufflenet主要将分组卷积用在Bottlenet结构的1*1卷积上,用1*1,3*3,1*1的卷积堆叠代替直接进行卷积操作。
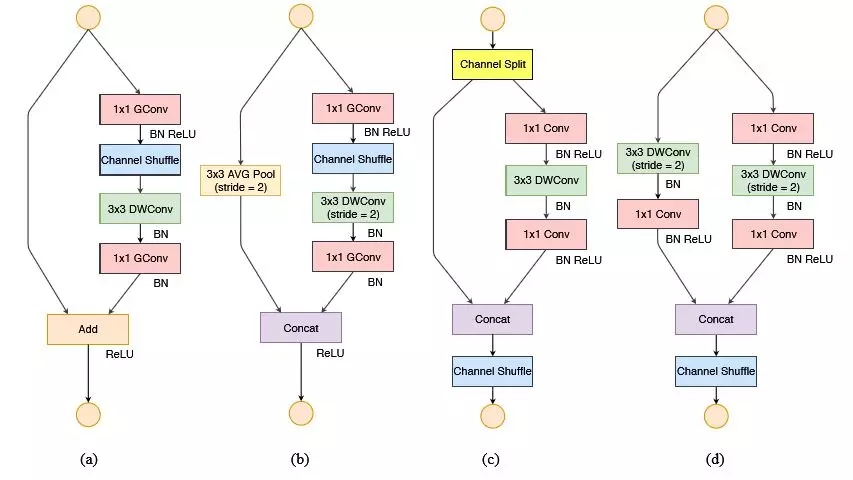
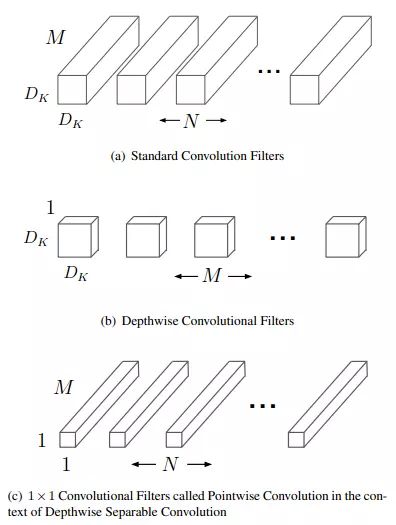
与此同时,MobileNet提出了深度可分离卷积,简单来说就是把输入的特征看成是1个Group,用3*3的分组卷积进行深度上的特征整合,然后再用1*1的卷积进行特征通道加权。
什么是梯度爆炸,什么是梯度消失,神经网络是怎么解决梯度爆炸问题的,ResNet为什么能够解决梯度消失问题?
将神经网络运算看成是矩阵乘法
\[F_{out}=A_{c_{out}\times c_{in}}\times F_{in}\]我们可以对A进行SVD分解
\[A=S_{c_{out}\times c_{out}}V_{c_{out}\times c_{in}}D_{c_{in}\times c_{in}}\]中间$V$是对角阵。如果对角元很多都大于1,那么深度神经网络求导的时候可能就会引起梯度爆炸,如果对角元很多都小于1,那么求导的时候就会导致梯度消失。神经网络通过BatchNorm来缓解梯度爆炸问题,而ResNet通过引入了恒等跳层连接,有点像是给$V$加了一个$\lambda I$来缓解梯度消失。
什么是规范化运算,有哪些规范化操作,它们各自有什么用
规范化运算是一种让输入统一分布的运算,对于输入$X$,它的一般形式是
\[X' = \frac{X-E(X)}{Std(X)}\]神经网络的规范化操作通过对$E(X)$与$Std(X)$进行估计,并在规范化后增加偏置项$\hat{X}=aX’+b$完成,注意a,b都是可学习的参数。
批正则化可以使得网络的输入同分布,并且令网络的输入不至于过大,从而缓解了梯度爆炸问题。
规范化操作包括BatchNorm,InstanceNorm与GroupNorm。BatchNorm最常用,在训练过程中,$E(X)$与$Std(X)$通过当前输入Batch的均值与之前步骤求得均值的滑动平均来获得,在测试过程中,用训练过程获得的均值与方差作为测试集的估计。实验发现,BatchNorm能够起到缓解过拟合的作用。
InstanceNorm常常用于生成模型,生成模型希望生成的样本较为丰富,样本间差异较大,因此用个体的规范化代替BatchNorm。
GroupNorm用于Batch数目较小,估计不稳定的情况,用特征组上的规范化代替了Batch层面的规范化。
有哪些梯度下降算法,它们各有什么异同。
一般有7种常用的梯度下降法,SGD, Momentum, Nesterov, Adagrad, Adadelta, Adam, 其中SGD, Momentum 与Adam是常用的。
SGD(随机梯度下降法)用当前Batch的梯度均值作为真实梯度的估计,而Momentum在此基础上更进一步,采用当前梯度与前面计算梯度的滑动平均作为梯度估计。这个策略是因为有统计发现,高维优化问题的难点在于优化过程中存在大量鞍点,而SGD会在鞍点处停滞,因此滑动平均相当于用前面的梯度加入了惯性,使得优化过程能够利用惯性冲过鞍点,继续下降。
Adam方法给出了模型优化过程自适应学习率的策略。如果把随机梯度下降法每一步梯度看成是随机变量,那么我们希望每一步学习率能够自适应调节,使得梯度的下降是平稳的,也就是需要对梯度做一个正则化。因此Adam方法用梯度的滑动平均除以梯度的二阶原点矩的滑动平均,自适应地调整学习率。
神经网络有哪些激活函数,为什么要用激活函数?
激活函数模拟了人体神经元对输入值的反射,它起到了限制数值的作用。神经网络本质是一种函数拟合的近似工具,有万能近似定理保证了,只要神经网络带有某种“范围挤压”性质的激活函数,那么理论上就可以拟合任意函数。因此,神经网络引入了ReLU,Sigmoid,Tanh,Softmax等激活函数。
ReLU在CNN中常常用,Sigmoid,Softmax常用于分类,而Tanh常用于反卷积。ReLU是最常用的激活函数,因为它有两种优点,前向和反向操作都很好算,而且梯度不容易消失。
通常有几种卷积形式
离散卷积(Dilation Convolution), 反卷积, 球面卷积(Sphere Convolution)。
什么是过拟合?深度学习的过拟合如何缓解?
过拟合一般指过度在训练集上进行优化,反而损害了测试集上的泛化能力的现象。一般出现训练集的loss下降,测试集的指标不降反增,就说明出现了过拟合。
在模型层面我们可以通过Early Stop, L1/L2 Normalization, Batchnorm, Dropout等方法进行缓解。
在输入数据层面,我们可以通过数据增广来进行缓解,如旋转,图像直方图正则化,以及Mixup等方法。
神经网络有什么初始化方法
神经网络有随机分布初始化(正态分布,均匀分布,一般均值选为0,方差选为0.01),Xavier初始化与Kaiming初始化。
Xavier初始化,目的是让正向传播与反向求导中,对于输入的随机变量X,其每一层的激活结果与求导结果的方差都为1.方差取输入的channel与输出channel的相加平均,如xavier正态初始化,卷积为输入16channel,输出64channel,卷积核3*3,那么Xavier下的方差为
\[\sqrt{\frac{2}{16*3*3+64*3*3}}\]Kaiming Normal指出,由于ReLU的存在,前向后向传播都应该减半计算,即在Xavier的基础上方差除2即可。
Pytorch与Tensorflow有什么区别
神经网络框架都是先构建计算图,然后在计算图上进行前向运算与反向传播,自动微分方法依赖于计算图。Pytorch是动态计算图,每次forward自动构建计算图,backward计算微分然后释放。Tensorflow是静态图,首先要构建一个session,session确定后静态图就确定了,前馈反馈都是基于这种静态图进行,而所有的操作都要 session.run(),有点像先编译再运行。
什么是联邦学习,联邦学习如何优化
略,用异步SGD优化