FengHZ‘s Blog首发原创
Introduction
Variational autoencoders are usually combined of 2 parts: an encoder to predict the posterior of latent variable $z$ given input $x$ written as $q(z\vert x)$ and a decoder to predict the posterior of input $x$ given $z$ written as $p(x\vert z)$. Then we use the ELBO in statistical inference area to build loss function
\[E_{\hat{p}(x)}[-\log p_{\theta}(x)] = \mathcal{L}_{VAE}(\theta,\phi) -E_{\hat{p}(x)}[\mathcal{D}_{KL}(q_{\phi}(z\vert x)\Vert p_{\theta}(z\vert x))] \tag{1}\]where
\[\mathcal{L}_{VAE}(\theta,\phi) = E_{\hat{p}(x)}[E_{q_{\phi}(z\vert x)}[-\log p_{\theta}(x\vert z)]] + E_{\hat{p}(x)}[D_{KL}(q_{\phi}(z\vert x)\Vert p_{\theta}(z))] \tag{2}\]To make $(2)$ have a closed form, we usually make some assumptions
\[p_{\theta}(z) \sim \mathcal{N}(0,I)\\ q_{\phi}(z\vert x) \sim \mathcal{N}(\mu,\Sigma)\\ p_{\theta}(x\vert z)\sim \mathcal{N}(\phi(z,\theta),\sigma^2)\]However, the basic ELBO loss may have some difficulties in training and the assumptions for prior and posterior distributions are too strong in some ways. In this note, we introduce some different loss function forms by rewriting $(2)$ and impose some meta-prior by adding different weights to different components of loss.
Here we list some commonly used forms along with the proof. Our main references are
-
Recent Advances in Autoencoder-Based Representation Learning
-
Adversarial Variational Bayes: Unifying Variational Autoencoders and Generative Adversarial Networks
-
Autoencoding beyond pixels using a learned similarity metric
Commonly used forms of ELBO
At the beginning, we may declare some symbols and tricks as following
\[\hat{p}(x) =\frac{\sum_{i} \delta(x_i=x)}{n}\\ q_{\phi}(z) = \sum_{i}q_{\phi}(z\vert x_i)\hat{p}(x_i)\\ q_{\phi}(z,x)= q_{\phi}(z\vert x) \hat{p}(x)\\ q_{\phi}(x\vert z) = \frac{q_{\phi}(z,x)}{q_{\phi}(z)}\\ p_{\theta}(x,z)=p_{\theta}(x\vert z)p(z)\]Mutual information form
We can rewrite $(2)$ in mutual information form as
\[E_{\hat{p}(x)}[D_{KL}(q_{\phi}(z\vert x)\Vert p_{\theta}(z))] = I_{q_{\phi}}(x;z) + \mathcal{D}_{KL}(q_{\phi}(z)\Vert p(z)) \tag{3}\]proof :
\[E_{\hat{p}(x)}[D_{KL}(q_{\phi}(z\vert x)\Vert p_{\theta}(z))] = \int_{x} \hat{p}(x)\int_{z}q_{\phi}(z\vert x)\log \frac{q_{\phi}(z\vert x)}{p(z)} dz dx \\ = \int_{x} \hat{p}(x)\int_{z}q_{\phi}(z\vert x)\log \frac{q_{\phi}(z\vert x)}{q_{\phi}(z)} dz dx + \int_{x} \hat{p}(x)\int_{z}q_{\phi}(z\vert x)\log \frac{q_{\phi}(z)}{p(z)} dz dx \\ = \int_{x}\int_{z}q_{\phi}(z,x)\log \frac{q_{\phi}(z, x)}{q_{\phi}(z)\hat{p}(x)} dz dx + \mathcal{D}_{KL}(q_{\phi}(z)\Vert p(z)) \\ = I_{q_{\phi}}(x;z) + \mathcal{D}_{KL}(q_{\phi}(z)\Vert p(z))\]Here we can get some insights from $(3)$. If we want to minimize $(3)$(as we want to minimize $(1)$), It appears that we need to minimize $I_{q_{\phi}}(x;z)$, which means the $x$ and $z$ will be independent and $z$ will not have enough information about $x$. So instead of minimize $(3)$ directly, we can give $I_{q_{\phi}}(x;z)$ a lower bound $C$ to make sure $z$ preserves enough information about $x$. In this opinion, we can rewrite the loss function $(2)$ as
\[\mathcal{L}_{VAE}(\theta,\phi) = E_{\hat{p}(x)}[E_{q_{\phi}(z\vert x)}[-\log p_{\theta}(x\vert z)]] + E_{\hat{p}(x)}[\vert D_{KL}(q_{\phi}(z\vert x)\Vert p_{\theta}(z))-C \vert]\]Disentangled form
Based on $(3)$, we can add disentanglement as meta-prior. Assuming that the data is generated from independent factors of variation, for example object orientation and lighting conditions in images of objects, making disentanglement as a meta-prior encourages these factors to be captured by different independent variables in the representation. To encourage this representation, we can use the following rewriting form
\[\mathcal{D}_{KL}(q_{\phi}(z)\Vert p(z))=\mathcal{D}_{KL}(q_{\phi}(z)\Vert \Pi_{j} q_{\phi}(z_j))(part.1)+ \sum_{j=1}^{n} \mathcal{D}_{KL}(q_{\phi}(z_j)\Vert p(z_j))(part.2) \tag{4}\]proof :
\[\mathcal{D}_{KL}(q_{\phi}(z)\Vert p(z)) = \int_{z} q_{\phi}(z)\log \frac{q_{\phi}(z)}{p(z)}dz \\ =\int_{z}q_{\phi}(z)\log \frac{q_{\phi}(z)}{\Pi_{j}q_{\phi}(z_j)}dz_1\ldots dz_n + \int_{z} q_{\phi}(z_1,\ldots,z_n)\log \frac{\Pi_{j}q_{\phi}(z_j)}{\Pi_{j}p(z_j)}dz_1\ldots dz_n\\ =\mathcal{D}_{KL}(q_{\phi}(z)\Vert \Pi_{j} q_{\phi}(z_j))+ \sum_{j=1}^{n} \mathcal{D}_{KL}(q_{\phi}(z_j)\Vert p(z_j))\]A widely used notation for
\[\mathcal{D}_{KL}(q_{\phi}(z)\Vert \Pi_{j} q_{\phi}(z_{j}))\]is $TC(q_{\phi}(z))$. We can assign high weight to the part.1 loss to ensure the entanglement.
Info-VAE
Info-VAE rewrites the ELBO as the KL divergency of $q_{\phi}(z),p(z)$ and $q_{\phi}(x\vert z),p_{\theta}(x\vert z)$
\[\mathcal{L}_{VAE}(\theta,\phi) =E_{\hat{p}(x)}[\mathcal{D}_{KL}(q_{\phi}(x\vert z)\Vert p_{\theta}(x\vert z))]\]proof :
\[E_{\hat{p}(x)}E_{q_{\phi}(z\vert x)}[\log p_{\theta}(x\vert z)+\log p(z)-\log q_{\phi}(z\vert x)]= E_{q_{\phi}(z\vert x)} [\log \frac{p_{\theta}(x,z)}{q_{\phi}(x,z)}+\log p_{\theta}(x)]\\ =-\mathcal{D}_{KL}[q_{\phi}(z,x)\Vert p_{\theta}(z,x)]+E_{\hat{p}(x)}E_{q_{\phi}(z\vert x)}\log \hat{p}(x)(\text{Const})\\ =_{\text{dump the const}}-\mathcal{D}_{KL}[q_{\phi}(z,x)\Vert p_{\theta}(z,x)]\\ =\int_{x}\int_{z}q_{\phi}(z,x)\log \frac{q_{\phi}(z,x)}{p_{\theta}(z,x)}dzdx \\ =\int_{x}\int_{z}q_{\phi}(z,x)\log \frac{q_{\phi}(z)}{p(z)}dzdx+\int_{x}\int_{z}q_{\phi}(z,x)\log \frac{q_{\phi}(x\vert z)}{p_{\theta}(x\vert z)}dzdx\\ =E_{\hat{p}(x)}[\mathcal{D}_{KL}(q_{\phi}(x\vert z)\Vert p_{\theta}(x\vert z))]\]Decomposition for the assumptions
To simplify the inference procedure, we proposes 2 assumptions separately for the prior and posterior distribution of latent variable $z$ and the posterior distribution of the input $x$ listed as following
\[q_{\phi}(z\vert x) = \mathcal{N}(\mu,\Sigma)\\ p(z) = \mathcal{N}(0,I) \tag{4}\] \[p_{\theta}(x\vert z) = \mathcal{N}(f(z,\theta),\sigma^2) \tag{5}\]However, it was observed that the reconstruction results often only vaguely resemble the input and the reconstruction result trained with mean square error only preserve the object considered salient and duplicate or average the small objects. To solve this problem, a set of adversarial methods have been proposed. Here we focus on 2 main methods target at $(4)$ and $(5)$ separately.
Use gan to measure the similarity
$(4)$ leads to the pixel-wise MSE Loss in the latent space, which is not very suitable for image data, as they do not model the properties of human visual perception. To deal with this problem, article combines GAN and VAE in reconstruction space to produce bette image samples. Following is the brief schematic.
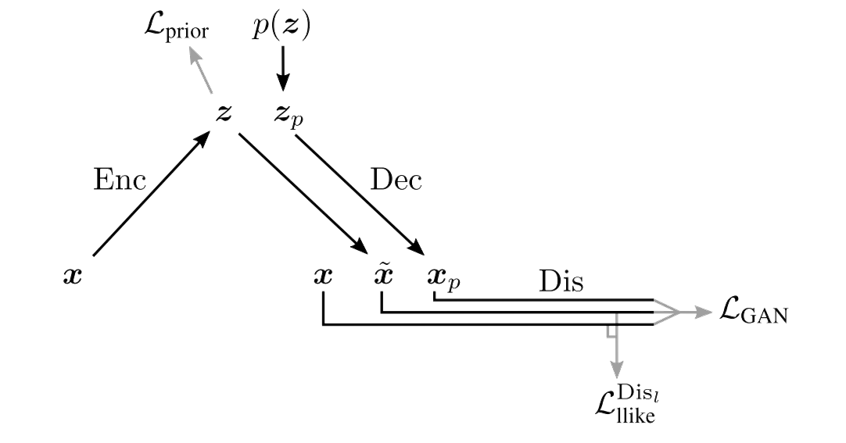
We can rewrite $(2)$ as
\[\mathcal{L}_{VAE}(\theta,\phi) = L^{pixel}_{llike}+ L_{prior}\\ L^{pixel}_{llike}=E_{\hat{p}(x)}[E_{q_{\phi}(z\vert x)}[-\log p_{\theta}(x\vert z)]]\\ L_{prior}=E_{\hat{p}(x)}[D_{KL}(q_{\phi}(z\vert x)\Vert p_{\theta}(z))]\]The article adds a discriminator network to the original VAE and uses the output feature in the l-th layer of discriminator to calculate
\[L^{Dis_{l}}_{llike}\]as an alternative to $L^{pixel}_{llike}$.
\[L^{Dis_{l}}_{llike} = -E_{\hat{p}(x)}[E_{q_{\phi}(z\vert x)}[\log p(\text{Dis}_{l}(x\vert z)]]\]The article also utilizes the discrimination loss for GAN
\[L_{GAN} = \log(\text{Dis}(x)) + \log(1-\text{Dis}(x_{reconstruct})) + \log(1-\text{Dis}(x_{generate})) \tag{6}\]In the training proceduer, we use adversarial method to train Encoder, Decoder and Discriminator step by step. Following is the algorithm
- input $x$
- use Encoder to calculate $\mu_z,\Sigma_z$
- $L_{prior}=\mathcal{D}_{KL}(q(z\vert x)\Vert p(z))$
- use Decoder to calculate $x_{reconstruct}$
- sample $z\sim p(z)$, use Decoder to generate $x_{generate}$
- calculate the l-th output feature of Discriminator as $\text{Dis}_{l}(x)$ and then calculate \(L^{Dis_{l}}_{llike} = -\log p(\text{Dis}_{l}(x) \vert z)\)
- use Decoder to calculate $L_{GAN} = \log(\text{Dis}(x)) + \log(1-\text{Dis}(x_{reconstruct})) + \log(1-\text{Dis}(x_{generate}))$
-
update the parameters step by step with SGD
- \[\theta_{Encoder} \leftarrow -\nabla_{\theta_{Enc}}(L_{prior}+L^{Dis_{l}}_{llike})\]
- \[\theta_{Decoder} \leftarrow -\nabla_{\theta_{Decoder} } (\gamma * L^{Dis_{l}}_{llike} - L_{GAN})\]
- \[\theta_{Discriminator} \leftarrow -\nabla_{\theta_{Discriminator}} L_{GAN}\]
The article also proposes an indicator to quantify the quality of the generation result. If we get the inference of latent variables for all images, we can get the attribute vector use the mean and minus method for one attribute with 0-1 label for each image. Then we can generate images with this specific attribute using the attribute vector. We can train a classifier independently to distinguish the attribute, and use the ratio that the classifier successfully identify the generated image to measure the generation quality.
Use adversarial training to get the precise posterior distribution
The assumptions $(4)$ of the prior and posterior distribution of latent variable $z$ lead to the closed form of the second part in $(2)$
\[E_{\hat{p}(x)}[D_{KL}(q_{\phi}(z\vert x)\Vert p_{\theta}(z))]\]The assumption that $q_{\phi}(z\vert x)$ is taken to be a Gaussian distribution with diagonal covariance matrix whose mean and variance vectors are parameterized by neural networks with $x$ as input is very restrictive, potentially limiting the quality of the resulting generative model. Indeed, it was observed that applying standard Variational Autoencoders to natural images often results in blurry images(it may also be a result of the pixel-wise MSE loss in input space).
A simple improvement is to use the adversarial density-ratio estimation. Given a convex function $f$ for which $f(1)=0$, then the f-divergence between $p_{x}$ and $p_{y}$ is defined as
\[\mathcal{D}_{f}(p_x\Vert p_y) = \int f(\frac{p_{x}(x)}{p_{y}(x)})p_{y}(x) dx\]For $p_{y}(x)$ is the prior and always has a closed form, we can use adversarial trick to estimate the density ratio $\frac{p_{x}(x)}{p_{y}(x)}$, which can be expressed as
\[\frac{p_{x}(x)}{p_{y}(x)} = \frac{p(x\vert c=1)}{p(x\vert c=0)} = \frac{p(c=1\vert x)}{p(c=0\vert x)}\approx \frac{S_{\eta}(x)}{1-S_{\eta}(x)}\]Notice here we assume $p(c=1)=p(c=0)$, so all we need is to train a discriminator to classify whether x is from $p_x$. Then we use the predicted score $S_{\eta}(x)$ to estimate the f-divergence and train VAE to minimize the f-divergence.
Another methood proposed in Adversarial Variational Bayes: Unifying Variational Autoencoders and Generative Adversarial Networks uses advsersarial method to get the exact value for
\[\log q_{\phi}(z\vert x) -\log p(z)\]We build an discriminator $T(x,z)$ which takes $(x,z)$ as input and tries to distinguish pairs $(x,z)$ that were sampled independently using the distribution $\hat{p}(x)p(z)$ from those that were sampled using the current inference model, i.e., using $\hat{p}(x)q_{\phi}(z\vert x)$. The loss function for discriminator is described as following
\[\max_{T} E_{\hat{p}(x)}E_{q_{\phi}(z\vert x)}\log \sigma(T(x,z)) + E_{\hat{p}(x)}E_{p(z)}\log (1-\sigma(T(x,z)) \tag{7}\]Here, $\sigma(t)=\frac{1}{1+e^{-t}}$, and we have the first proposition to demonstrate the contribution of $(7)$
- Proposition 1. For $p_{\theta}(x,\vert z)$ and $q_{\phi}(z\vert x)$ fixed, the optimal discriminator $T^{\star}$ according to the objective in $(7)$ is given by \(T^{\star}(x,z) = \log q_{\phi}(z\vert x) -\log p(z) \tag{8}\) See the applendix for the details of the proof
Together with $(2)$, Proposition 1. allows us to write the ELBO as
\[\max_{\theta,\phi} E_{\hat{p}(x)}E_{q_{\phi}(z\vert x)}(-T^{\star}(x,z)+\log p_{\theta}(x\vert z)) \tag{9}\]However, in $(9)$ we don’t give the analytical form of $q_{\phi}(z\vert x)$, so how to sample from $q_{\phi}(z\vert x)$ is a big question. The article modifies the basic VAE form and proposes an implicit sample method as the following schematic shows
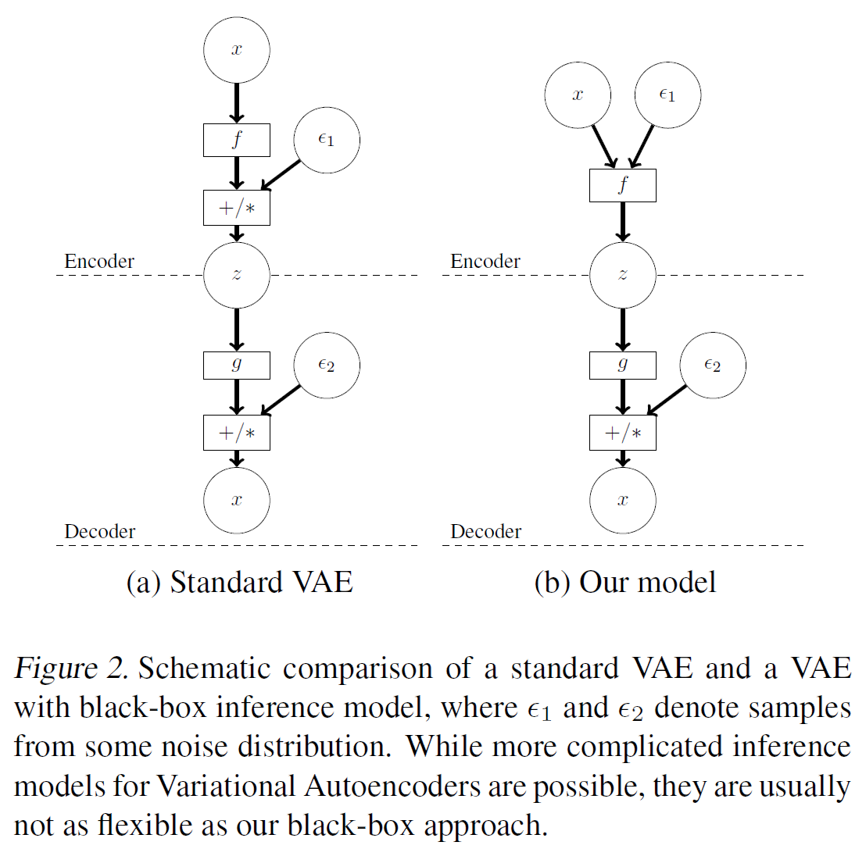
Here we also use reparametrization trick but we inject noise on the top and let the learned function $f$ to do sample and inference together. Use this structure, we can directly sample $z$ using neural network with noise $\epsilon_1$. If we want to get another sample, then we just need to resample the noise $\epsilon_1$ and let the neural network predict $z \sim q_{\phi}(z\vert x)$.
To optimize $(9)$ we need to calculate the gradient with respect to $\theta$ and $\phi$. However, the parameter $\psi$ for $T^{\star}$ are optimized by $(7)$, which is related to $\phi$. But the gradient $\frac{\partial \psi}{\partial \phi}$ can’t be calculated directly, and we need the second proposition to handle this problem
- Proposition 2. We have \(E_{q_{\phi}(z\vert x)}[\nabla _{\phi}T^{\star}(x,z,\psi)=0]\) See the applendix for the details of the proof
Use the conclusion of Proposition 2, we can just fix the parameter $\psi$ in $T^{\star}$ and view $T^{\star}$ as an fixed optimization target. Then we can derive a target loss function for $\theta,\phi$ as following
\[\max_{\theta,\phi}E_{\hat{p}(x)}E_{\epsilon}(-T^{\star}(x,z_{\phi}(x,\epsilon))+\log p_{\theta}(x\vert z_{\phi}(x,\epsilon))) \tag{10}\]Combined with $(7)$ , we can derive a two-player game with parameter $(\theta,\phi,\psi)$
\[\max _{\psi} E_{\hat{p}(x)}E_{q_{\phi}(z\vert x)}\log \sigma(T_{\psi}(x,z)) + E_{\hat{p}(x)}E_{p(z)}\log (1-\sigma(T_{\psi}(x,z)) \tag{11}\]And assume that $T$ can represent any function of two variables and $q_{\phi}(z\vert x)$ can represent any probability density on the latent space(universal approximation theorem in deep learning), if the $(\theta^{\star},\phi^{\star},\psi^{\star})$ defines a Nash-equilibrium of this two-player game, then we have the third proportion which decludes a beautiful, very strong and perfect result and gives us some useful and siginificant insights in the power of the adversarial method
-
Proposition 3. Assume that $T$ can represent any function of two variables and $q_{\phi}(z\vert x)$ can represent any probability density on the latent space. If the $(\theta^{\star},\phi^{\star},\psi^{\star})$ defines a Nash-equilibrium of this two-player game, then we have
- $(\theta^{\star},\phi^{\star})$ is the global optimum of the ELBO in $(2)$
- $q_{\phi^{\star}}$ is equal to the true posterior $p_{\theta^{\star}}(z\vert x)$ (Powerful!)
- $T^{\star}$ is the pointwise mutual information between $x$ and $z$, i.e. \(T^{\star}(x,z) = \log \frac{p_{\theta^{\star}}(x,z)}{p(x)p(z)}\)
See the applendix for the details of the proof
Based on the proposition 3, the article raises an algorithm for the adversarial strategy$(eq. 3.7 = (10),eq. 3.3 = (11))$
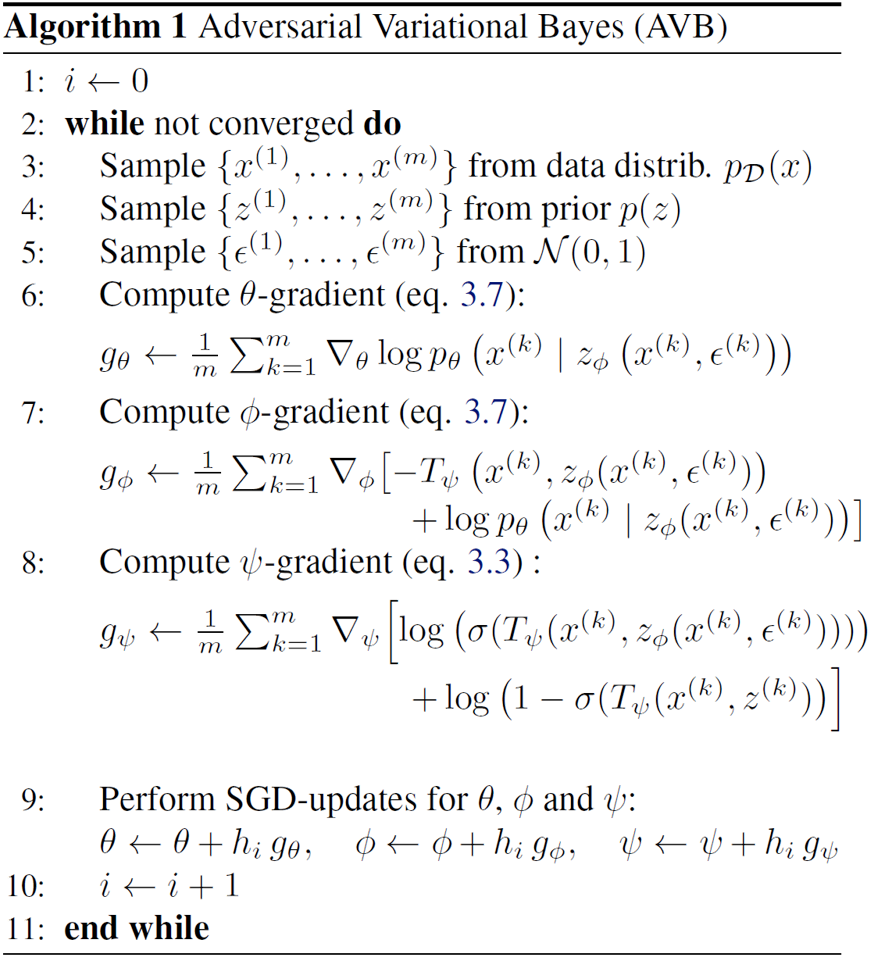
However, the stable training strategy of the algorithm is very difficult, for $T$ aims to distingush the two distribution $q_{\phi}(z\vert x) and p_{z}$, which are usually very different and easy to differentiate and will make discriminator too strong. To improve the quality of the estimate, the article propose to introduce an auxiliary conditional probability distribution $r_{\alpha}(z\vert x)$ with known density to approximates $q_{\phi}(z\vert x)$. We usually assume that $r_{\alpha}(z\vert x)$ is a Gaussian distribution with diagnoal covariance matrix whose mean and variance matches that of $q_{\phi}(z\vert x)$.
Utilizing this auxiliary distribution, we can rewrite ELBO as
\[ELBO(\theta,\phi) = E_{\hat{p}(x)}[E_{q_{\phi}(z\vert x)}[\log p_{\theta}(x\vert z)-\log \frac{q_{\phi}(z\vert x)}{p(z)}]] \\ =E_{\hat{p}(x)}[E_{q_{\phi}(z\vert x)}[\log p_{\theta}(x\vert z)-\log \frac{q_{\phi}(z\vert x)}{r_{\alpha}(z\vert x)}-\log \frac{r_{\alpha}(z\vert x)}{p(z)}]] \\ = E_{\hat{p}(x)}[E_{q_{\phi}(z\vert x)}[\log p_{\theta}(x\vert z)+ \log p(z) - \log r_{\alpha}(z\vert x)]] -E_{\hat{p}(x)}[D_{KL}(q_{\phi}(z\vert x)\Vert r_{\alpha}(z\vert x))] \tag{12}\]In practice, we use $T$ to distinguish pair $(x,z)$ that sampled using $\hat{p}(x)r_{\alpha}(z\vert x)$ from pair $(x,z)$ that sampled using $\hat{p}(x)q_{\phi}(z\vert x)$, and we rewrite the two-players game $(10),(11)$ into the following form:
\[\max _{\psi} E_{\hat{p}(x)}E_{q_{\phi}(z\vert x)}\log \sigma(T_{\psi}(x,z)) + E_{\hat{p}(x)}E_{r_{\alpha}(z\vert x)}\log (1-\sigma(T_{\psi}(x,z)) \tag{12}\] \[\max_{\theta,\phi}E_{\hat{p}(x)}E_{\epsilon}(-T^{\star}(x,z_{\phi}(x,\epsilon))+\log p_{\theta}(x\vert z_{\phi}(x,\epsilon))+\log p(z) - \log r_{\alpha}(z\vert x)) \tag{13}\]Here $T^{\star}(x,z_{\phi}(x,\epsilon))$ is supposed to be \(T^{\star}(x,z_{\phi}(x,\epsilon)) = \log q_{\phi}(z\vert x) -\log r_{\alpha}(z\vert x)\)
To estimate the mean and variance of $r_{\alpha}(z\vert x)$, we can simply sample $\epsilon$ many times and calculate the mean and std as the estimation. Another method is to use the network to predict $\mu$ and $\sigma$ for $z$ and do normalization with
\[\bar{z}_{\phi} = \frac{z_{\phi}-\mu}{\sigma}\]then we can view
\[r_{\alpha}(\bar{z}\vert x)\sim \mathcal{N}(0,I)\]Following are the algorithm with adaptive contrast method
- Algorithm 2 Adversarial Variational Bayes with Adaptive Contrast
- $i \leftarrow 0$
- while not converged do
- sample ${x^{(1)},\ldots,x^{(m)}}$ from $\hat{p}(x)$
- sample ${\epsilon^{(1)},\ldots,\epsilon^{(m)}}$ from $\mathcal{N}(0,1)$
- sample ${\eta^{(1)},\ldots,\eta^{(m)}}$ from $\mathcal{N}(0,1)$
-
for k =1,…,m do
- \[z_{\phi}^{(k)},\mu^{(k)},\sigma^{(k)} =encoder_{\phi}(x^{(k)},\epsilon^{(k)})\]
- \[\bar{z}_{\phi}^{(k)} = \frac{z_{\phi}^{(k)}-\mu^{(k)}}{\sigma^{(k)}}\]
- end for
-
compute $\theta$-gradient
\[g_{\theta} = \frac{1}{m}\sum_{k=1}^{m}\nabla_{\theta}\log p_{\theta}(x^{(k)}\vert z_{\phi}^{(k)})\] -
compute $\phi$-gradient
\[g_{\phi} = \frac{1}{m}\sum_{k=1}^{m}\nabla_{\phi}[-T_{\psi}(x^{(k)},\bar{z}_{\theta}^{(k)})+\log p_{\theta}(x^{(k)}\vert z_{\phi}^{(k)})+\frac{1}{2}\Vert \bar{z}_{\phi}^{(k)} \Vert^2 +\log p(\bar{z}_{\phi}^{(k)})]\] -
compute $\psi$-gradient
\[g_{\psi} = \frac{1}{m}\sum_{k=1}^{m} \nabla_{\psi}[\log \sigma(T_{\psi}(x^{(k)},\bar{z}_{\phi}^{(k)}))+\log (1-\sigma(T_{\psi}(x^{(k)},\eta^{(k)})))]\] - perform SGD-updates for $\theta,\phi,\psi$ with $g_{\theta},g_{\phi},g_{\psi}$
- i = i+1
- end while
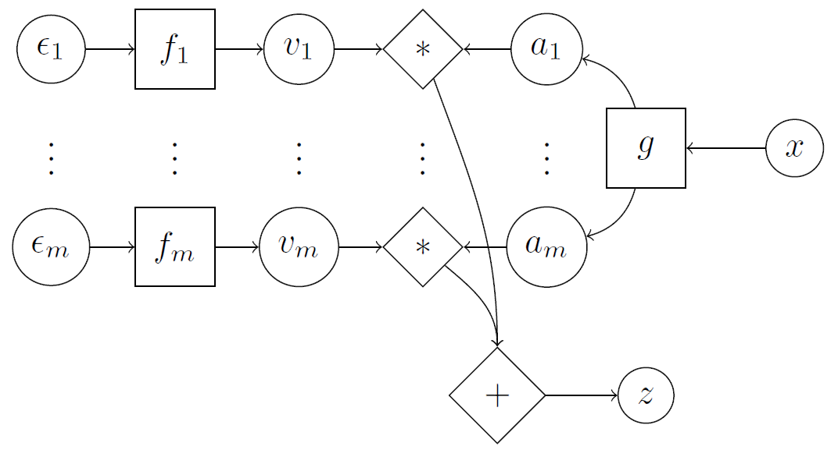
When it comes to how to combine $\epsilon$ with $x$, the article suggests the inner product
\[z_{k} = \sum_{i=1}^{m} v_{i,k}(\epsilon_{i})a_{i,k}(x)\]and we have
\[E(z_{k})=\sum_{i=1}^{m}E[v_{i,k}(\epsilon_{i})]a_{i,k}(x)\\ Var(z_{k}) = \sum_{i=1}^{m}Var[v_{i,k}(\epsilon_{i})]a_{i,k}(x)\]The details are illustrated in the following schematic
Applendix
Some notes on KL-Divergency
\[\mathcal{D}_{KL}(p\Vert q) = \int_{z}p(z_1,\ldots,z_n)\log \frac{p(z_1,\ldots,z_n)}{q(z_1,\ldots,z_n)}dz_1\ldots dz_n\]-
Suppose $p(z_1,\ldots,z_n)=\Pi p(z_j),q(z_1,\ldots,z_n)=\Pi q(z_j)$, then we have \(\mathcal{D}_{KL}(p\Vert q) =\sum_{j}\mathcal{D}_{KL}(p(z_j)\Vert q(z_j))\)
-
Suppose we only assume $q(z_1,\ldots,z_n)=\Pi q(z_j)$, then we have \(\mathcal{D}_{KL}(p\Vert q) =\mathcal{D}_{KL}[p(z)\Vert \Pi_{j}p(z_j)]+\sum_{j=1}^{n}\mathcal{D}_{KL}[q(z_j)\Vert p(z_j)]\)
Proof for proposition 1.
We can rewirte $(7)$ in an integral form
\[\max _{T} \int_{x}\int_z [\hat{p}(x)q_{\phi}(z\vert x) \log \sigma(T(x,z))+\hat{p}(x)p(z) \log \sigma(T(x,z))] dz dx \tag{A.1}\]As the functions $\hat{p}(x),p(z),q_{\phi}(z\vert x)$ are given, we may rewrite $(A.1)$ as the limit form
\[\max _{T} \sum_{i=1}^{N}\sum_{j=1}^{M}[\hat{p}(x_{i})q_{\phi}(z_{j}\vert x_{i}) \log \sigma(T(x_{i},z_{j}))+\hat{p}(x_{i})p(z_{j}) \log(1- \sigma(T(x_{i},z_{j})))] \Delta_{z} \tag{A.2}\]A natural thought is that if we can get the maximum for each part
\[\hat{p}(x_{i})q_{\phi}(z_{j}\vert x_{i}) \log \sigma(T(x_{i},z_{j}))+\hat{p}(x_{i})p(z_{j}) \log (1-\sigma(T(x_{i},z_{j}))) \tag{A.3}\]Then we can get the maximum of $(A.2)$. Utilizing the result that the function
\[a\log (t) +b \log (1-t)\]achieves it’s maximum at $t=\frac{a}{a+b}$, so we can get that
\[\sigma(T^{\star}(x_{i},z_{j})) = \frac{\hat{p}(x_{i})q_{\phi}(z_{j}\vert x_{i}) }{\hat{p}(x_{i})q_{\phi}(z_{j}\vert x_{i})+\hat{p}(x_{i})p(z_{j}) }\]and then use $\sigma(t)=\frac{1}{1+e^{-t}}$, we can get
\[T^{\star}(x,z) = \log q_{\phi}(z\vert x) -\log p(z)\]Proof for proposition 2.
\[E_{q_{\phi}(z\vert x)}[\nabla _{\phi}T^{\star}(x,z,\psi)=0] \tag{A.4}\]Use proposition 1, we have
\[T^{\star}(x,z,\psi) = \log q_{\phi}(z\vert x) - \log p(z)\]Then
\[E_{q_{\phi}(z\vert x)}(\nabla_{\phi}T^{\star}(x,z,\psi)) = E_{q_{\phi}(z\vert x)} (\nabla_{\phi} \log q_{\phi}(z\vert x))\\ =\int q_{\phi}(z)\frac{\nabla_{\phi}q_{\phi}(z)}{q_{\phi}(z)}dz\\ =\int \nabla_{\phi}q_{\phi}(z)dz\\ =\nabla_{\phi}\int q_{\phi}(z)dz = \nabla_{\phi} 1 =0\]Here we use the conclusion $\nabla_{\phi}\int = \int\nabla_{\phi}$ without proof, but we can give a simple insight from the real analysis book written by Folland:
-
Theorem 2.27 Suppose that $f:X\times [a,b] \rightarrow C(-\infty <a<b<\infty)$ and that $f(.,t):X\rightarrow C$ is integrable for each $t \in [a,b]$. Let $F(t)=\int_{X}f(x,t)d\mu(x)$. Suppose that $\frac{\partial f}{\partial t}$ exists and there is a $g\in L^{1}(\mu)(\text{note 1})$ s.t. that $\vert \frac{\partial f}{\partial t}(x,t) \vert \leq g(x)$ for all $x,t$. Then $F$ is differentiable and we have
\[\frac{\partial F(t)}{\partial t} = \partial \int_{X}f(x,t)d\mu(x)/\partial t = \int_{X}\frac{\partial f(x,t)}{\partial t}d\mu(x)\]- note 1:definition We define $L^{1}(\mu)$ to be the collection of all complex measurable functions $f$ on $X$ for which
Proof for proposition 3.
For given $(\theta^{\star},\phi^{\star})$e can easily get
\[T^{\star}_{\psi}(x,z) = \log q_{\phi^{\star}}(z\vert x) -\log p(z) \tag{A.5}\]which is illustrated in proposition 1. Inserting $(A.5)$ into $(10)$ shows that $(\phi^{\star},\theta^{\star})$ maximizes
\[E_{\hat{p}(x)}E_{q_{\phi}(z\vert x)}(\log p_{\theta}(x\vert z)+\log p(z)-\log q_{\phi^{\star}}(z\vert x))\tag{A.6}\]which is equals to
\[E_{\hat{p}(x)}E_{q_{\phi}(z\vert x)}(\log p_{\theta}(x\vert z)+\log p(z)-\log q_{\phi}(z\vert x)) +E_{\hat{p}(x)}E_{q_{\phi}(z\vert x)} \log \frac{q_{\phi}(z\vert x)}{ q_{\phi^{\star}}(z\vert x)} \\ =ELBO + E_{\hat{p}(x)}\mathcal{D}_{KL}[q_{\phi}(z\vert x) \Vert q_{\phi^{\star}}(z\vert x)]\tag{A.7}\]Suppose the pair $(\phi^{\star},\theta^{\star})$ doesn’t maximize $(2)$, then there is another pair $(\phi^{‘},\theta^{‘})$ satisify that
\[ELBO(\phi^{'},\theta^{'})>ELBO(\phi^{\star},\theta^{\star})\]and
\[E_{\hat{p}(x)}\mathcal{D}_{KL}[q_{\phi^{'}}(z\vert x) \Vert q_{\phi^{\star}}(z\vert x)] > 0\]which is contradict to the statement in $(A.6)$. So we have the pair $(\phi^{\star},\theta^{\star})$ maximizes $(2)$, which is correct if and only if
\[\mathcal{D}_{KL}(q_{\phi^{\star}}(z\vert x) \Vert p(z\vert x)) =0\]