在所有机器学习与深度学习的模型落地中,域偏移(Domain Shift),即训练数据与真实数据来自于不同的分布,是一个很常见的问题,而这个问题在很多落地场景中都是很致命的。如在医学深度学习模型中,用A医院的数据(Source Domain)训练的模型往往在B医院(Target Domain)预测不准。在摄像头行人重识别(Re-ID)问题中,多个摄像头捕捉的场景分布完全不一致,导致单个行人在多个摄像头中的”重识别”变得较为困难。在联邦学习问题中,我们会单独获得多个数据源的数据,而只有部分数据有标签,这使得我们利用某些数据源的标签对其他数据进行建模的过程中也会出现偏移。有很多学者对这个问题做了不同的诠释,提供了不同的解决办法。有些流派将该问题解释为 “covariate shift”, 认为解决该方法需要对每一个样本进行赋权操作。还有的流派将解决该问题的办法称作迁移学习(Transfer Learning), 通过先后训练与特征微调来bridge the gap. 以上流派着眼于方法论,其思想与文章写作都偏向实用主义。我比较喜欢的流派是以域适应(Domain Adaptation)作为解决办法的流派,该流派的基础思想是,在保持源域任务精度的前提下,缩小模型所习得的表示空间上源域与目标域的特征距离。本文主要介绍该流派自洽的数学表达,同时介绍现在较为实用的算法,包括对抗域迁移学习,以及联邦对抗域迁移学习。
本文主要参考文献为:
- A Theory of learning from different domains
- Analysis of Representations for Domain Adaptation
- Domain-Adversarial Training of Neural Networks
- Federated Adversarial Domain Adaptation
- CYCADA: Cycle-Consistent Adversarial Domain Adaptation
Domain Adaptation: 基本定义
从上文中的几个例子,我们大概隐隐约约知道了Domain Adaptation是解决两个数据集分布不一致的一种办法。但是,要给出严谨的数学定义,我们仍然要思考一些问题,比如,我们应该如何用符号来严格刻画Domain与Domain Shift呢?任意给两个不一样的数据集,我们都可以进行Domain Adaptation吗?对于两个域之间距离应该如何计算呢?给定的度量是否可以用样本进行经验估计呢?这些问题是定义上的问题。此外,在现实场景中,我们所需要处理的数据源是复杂的,有可能Source Domain和Target Domain都有充足的数据和标签,有可能只有Source Domain有标签,还有可能有充足的Source和Target Domain的源数据,但是两个数据集都只有部分标签。在这些场景下,如何去分配Source Domain和Target Domain的权重,这又是一个重要的问题。良好地描述一个问题,是解决一个问题的前提。在本节中,我们在概率论的角度,给出Domain以及Domain Adaptation的基本定义。
我们用如下的数学形式刻画在二分类任务上的Domain Adaptation问题。首先,我们将输入集记为$\mathcal{X}$,标注空间是一个概率空间,因为是二分类问题,我们的标注集就是$[0,1]$区间。在$\mathcal{X}$上,我们定义一个domain是由$<\mathcal{D},f>$所构成的一个对。其中,$\mathcal{D}$是一个分布函数,刻画输入集$\mathcal{X}$上每个样本的出现概率,而$f$是一个标签函数,$f:\mathcal{X}\rightarrow [0,1]$,表示从输入集到标注集的一个映射,其中,$f(\mathbf{x})\in [0,1],x\in \mathcal{X}$可以是$[0,1]$区间内的任意实数值,表示样本$\mathbf{x}$的标签为1的概率。一般而言,我们用字母$S,T$区分源域(Source Domain)和目标域(Target Domain),而两个域的数学表示分别记为$<\mathcal{D}_S,f_S>$和$<\mathcal{D}_T,f_T>$。
给定两个域$<\mathcal{D}_S,f_S>$与$<\mathcal{D}_T,f_T>$后,我们希望学习一个函数$h:\mathcal{X}\rightarrow{0,1}$,这个目标函数直接预测输入所对应的标签,我们把这个模型习得的函数$h$称作是一个假设(hypothesis),将$h$与$f$的差距记作
\[\epsilon(h,f;\mathcal{D})= \mathbf{E}_{\mathbf{x}\sim \mathcal{D}}\vert h(\mathbf{x})-f(\mathbf{x})\vert \tag{1}\]为简化标记,在源域上,我们记$\epsilon_S(h)=\epsilon_S(h,f_S;\mathcal{D}_S)$,如果我们只有有限的样本,则我们采用这些样本对$(1)$的期望进行经验估计,记经验估计的结果为$\hat{\epsilon}_S(h)$。同样地,我们可以得到$\epsilon_T(h),\hat{\epsilon}_T(h)$.
给定两个domain$<\mathcal{D}_S,f_S>$和$<\mathcal{D}_T,f_T>$,我们采用基于$L_1$范数的变分散度(Variational Distance)来刻画它们的距离,即
\[d_1(\mathcal{D}_S,\mathcal{D}_T) = 2 \sup_{B\subset \mathcal{X}}\vert \Pr_{\mathcal{D}_S}(B)-\Pr_{\mathcal{D}_T}(B)\vert \tag{2}\]其中,$\Pr(B)$表示集合$B$的概率。这个距离可以这么理解,我们找两个不同数据分布上分布差距最大的子集,将它们的概率的差值绝对值作为距离。但是,实际使用过程中,该距离又有诸多不便。首先,如果分布函数是离散的,那么找到$(2)$的上确界就是一个NP-Hard问题。其次,如果分布函数是连续的,那么$(2)$中取得上确界的$B$往往是由多个小区间联立拼凑而成,这实际上是无法计算的,因此该距离的计算意义不大。但是该距离却具有很高的实际用处。我们做Domain Adaptation,是希望在源域$\mathcal{D}_S$上训练的模型$h$能泛化到目标域$\mathcal{D}_T$上,即希望$\epsilon_S(h)$很小的时候,$\epsilon_T(h)$也比较小,这个时候,$(2)$中刻画的距离就给出了一个很漂亮的不等式,我们先不加证明地将其写出:
\[\epsilon_T(h)\leq \epsilon_S(h)+d_1(\mathcal{D}_S,\mathcal{D}_T) +\min \{\mathbf{E}_{\mathcal{D}_S}\vert f_S(\mathbf{x})-f_T(\mathbf{x})\vert,\\ \mathbf{E}_{\mathcal{D}_T}\vert f_S(\mathbf{x})-f_T(\mathbf{x})\vert \} \tag{3}\]该不等式表示,在$\mathcal{D}_S$上训练的$h$,当$\epsilon_S(h)$很小的时候,$\epsilon_T(h)$是否也比较小,这取决于两个数据集的距离以及两个数据集的标签函数$f_S,f_T$是否一致。但是,$(3)$所展现出对于$\epsilon_T(h)$的上确界确实过于宽松了。一个很典型的想法是,我的模型只需要关注于对学到的假设$h$而言,两个数据集的距离不会很远就行了。在现实任务中,如果我有Domain Adaptation的需求,那么在目标任务上,这两个数据集应该是有一定相似度的,那么我们为什么要考虑整个数据分布的距离呢?是否只需要考察在目标假设$h$上的距离就够了呢?在这个思想下,$\mathcal{H}$距离被提出了
\[d_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)=2 \sup_{h\in \mathcal{H}}\vert \Pr_{\mathcal{D}_S}(I(h))-\Pr_{\mathcal{D}_T}(I(h))\vert \tag{4}\]其中,$\mathcal{H}$是我们模型训练出的所有可能假设$h$的集合,我们可以把它看成是模型容量,$I(h)={\mathbf{x}:h(\mathbf{x})=1,\mathbf{x}\in \mathcal{X}}$是$\mathcal{X}$的一个子集,但是与$h$有关。通过$(4)$的定义,我们就把数据集的距离与目标假设联系在一起了。
Domain Adaptation:几个重要的Bound
从Domain Adaptation的一系列定义中,我们大概已经有了一种感觉,即Domain Adaptation主要目的是想通过一系列手段,使得优化$\epsilon_S(h)$所得到的模型$h$同样能在$\epsilon_T(h)$上得到很好的表现。为此,我们需要建立这两者的联系,以得到以下形式的Bound:
\[\epsilon_T(h)\leq \epsilon_S(h)+A+B+C\]在上文中,我们已经通过$(3)$给出了一个重要的Bound,它表明,$\epsilon_T(h)$的上确界与优化$\epsilon_S(h)$有关,同时也与数据集之间的差异,以及数据集的标签函数$f_S,f_T$之间的差异有关。但是,$(3)$所刻画的Bound固然具有良好的分析形式,却并不实用,其中涉及到$d_1(\mathcal{D}_S,\mathcal{D}_T),f_S,f_T$这几项更是无法得到。因此,我们需要一些能过计算的Bound来提供实践指导。同时,在列举出这些Bound的同时,我们同样给出了这些Bound的证明,它可以帮我们理解为什么要如此定义距离。
Bound$(3)$回顾与证明
我们看到$(2)$,$(4)$两个距离的时候,应当产生的一个疑惑是,为什么这些距离前面都有一个系数2。在这里,我们通过回顾证明Bound$(3)$来解决这一问题。
\[\epsilon_T(h)\leq \epsilon_S(h)+d_1(\mathcal{D}_S,\mathcal{D}_T) +\min \{\mathbf{E}_{\mathcal{D}_S}\vert f_S(\mathbf{x})-f_T(\mathbf{x})\vert,\\ \mathbf{E}_{\mathcal{D}_T}\vert f_S(\mathbf{x})-f_T(\mathbf{x})\vert \} \tag{3}\]证明:
\[\epsilon_T(h) = \epsilon_T(h) + \epsilon_S(h) - \epsilon_S(h) +\epsilon_S(h,f_T) - \epsilon_S(h,f_T)\\ \leq \epsilon_S(h) +\vert \epsilon_S(h,f_T)-\epsilon_S(h) \vert + \vert \epsilon_T(h) - \epsilon_S(h,f_T) \vert\]首先
\[\vert \epsilon_S(h,f_T)-\epsilon_S(h) \vert =\vert \mathbf{E}_{\mathcal{D}_S}[\vert h-f_T\vert -\vert h-f_S\vert ]\vert \\ \leq \mathbf{E}_{\mathcal{D}_S}\vert\vert h-f_T\vert -\vert h-f_S\vert \vert\]注意到 $h(\mathbf{x})\in {0,1}$,同时$f_S(\mathbf{x}),f_T(\mathbf{x})\in [0,1]$,因此$\vert\vert h-f_T\vert -\vert h-f_S\vert \vert$可以简化为$\vert f_T-f_S\vert$。(Note:分别考虑$h(\mathbf{x})=0,1$的两种情况代入即可。)
其次,我们来证明
\[\vert \epsilon_T(h) - \epsilon_S(h,f_T) \vert \leq d_1(\mathcal{D}_S,\mathcal{D}_T)\]我们有
\[\vert \epsilon_T(h) - \epsilon_S(h,f_T) \vert = \vert \int_{\mathcal{X}}\vert h(\mathbf{x})-f_T(\mathbf{x})\vert (\phi_{T}(\mathbf{x})-\phi_{S}(\mathbf{x}))dx\vert\]取
\[\mathcal{X}=\mathcal{X}_{1}\cup\mathcal{X}_{2}\]其中
\[\mathcal{X}_1=\{\mathbf{x}:\phi_{T}(\mathbf{x})>\phi_{S}(\mathbf{x}))\},\mathcal{X}_2=\{\mathbf{x}:\phi_{T}(\mathbf{x})\leq\phi_{S}(\mathbf{x}))\}\]我们可以用 $\mathcal{X}$ 的拆分将上述等式右边转化为
\[\vert \int_{\mathcal{X}}\vert h(\mathbf{x})-f_T(\mathbf{x})\vert (\phi_{T}(\mathbf{x})-\phi_{S}(\mathbf{x}))dx\vert =\\ \vert \int_{\mathcal{X}_1}\vert h(\mathbf{x})-f_T(\mathbf{x})\vert (\phi_{T}(\mathbf{x})-\phi_{S}(\mathbf{x}))dx + \int_{\mathcal{X}_2}\vert h(\mathbf{x})-f_T(\mathbf{x})\vert (\phi_{T}(\mathbf{x})-\phi_{S}(\mathbf{x}))dx\vert\\ \leq \vert \int_{\mathcal{X}_1}\vert h(\mathbf{x})-f_T(\mathbf{x})\vert (\phi_{T}(\mathbf{x})-\phi_{S}(\mathbf{x}))dx\vert +\vert \int_{\mathcal{X}_2}\vert h(\mathbf{x})-f_T(\mathbf{x})\vert (\phi_{S}(\mathbf{x})-\phi_{T}(\mathbf{x}))dx\vert\]注意到$\vert h(\mathbf{x})-f_T(\mathbf{x})\vert\leq 1$,那么我们可以把不等式扩展到
\[\leq \vert \Pr_{\mathcal{D_S}}(\mathcal{X}_1)-\Pr_{\mathcal{D_T}}(\mathcal{X}_1)\vert +\vert \Pr_{\mathcal{D_S}}(\mathcal{X}_2)-\Pr_{\mathcal{D_T}}(\mathcal{X}_2)\vert\\ \leq d_1(\mathcal{D}_S,\mathcal{D}_T)\]那么上述不等式得证,而系数2的来历,则是源于我们对原始输入集合$\mathcal{X}$进行的两阶段拆分。
通过VC维构建Bound计算$d_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)$
我们在上文中提到,距离
\[d_1(\mathcal{D}_S,\mathcal{D}_T)\]是无法计算的,而针对某一具体的任务,我们提到了用 $d_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)$来代替。显而易见的是
\[d_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)\leq d_1(\mathcal{D}_S,\mathcal{D}_T)\]是一个下界。那么,两个重要的问题是,如何计算$d_{\mathcal{H}}$,以及如何通过$d_{\mathcal{H}}$构建$\epsilon_T(h)$与$\epsilon_S(h)$之间的关系。本节中,我们先介绍如何通过经验样本计算$d_{\mathcal{H}}$。假如我们对源域与目标域的数据分布分别采样相同的个数$m$个,构成样本集$U_S,U_T$,那么$d_{\mathcal{H}}$的经验表达形式为
\[\hat{d}_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)=2\sup_{h \in \mathcal{H}}\vert \frac{1}{m}\sum_{i=1}^{m}\mathbf{I}[h(\mathbf{x_i})=1]-\frac{1}{m}\sum_{i=1}^{m}\mathbf{I}[h(\mathbf{x_i})=1]\vert \tag{4}\]但是,这个经验表达形式仍然涉及一个上确界问题,如何通过某种办法找到合适的$h$,从而进行计算呢?首先,考虑如何计算在某个假设空间上$\mathcal{D}_S,\mathcal{D}_T$的距离。我们知道,$d_1(\mathcal{D}_S,\mathcal{D}_T)$距离的本质是在分布函数上去找两个数据集”差异最大的地方”。那么,对于某一类假设空间(分类器空间)$\mathcal{H}$,如果这个空间上,存在分类器完全无法区分数据是来源于$\mathcal{D}_S$还是$\mathcal{D}_T$,说明这个假设空间对于两个数据集的距离 “很小”。依据这种思路,我们可以给$\mathcal{D}_S$打上标签0,$\mathcal{D}_T$打上标签1,然后在整个假设空间上去找一个分类器,这个分类器尽量区分输入的数据是来自于源域分布$\mathcal{D}_S$还是来自于目标域分布$\mathcal{D}_T$。这样的分类器是很好找的,因为这本质是一个二分类问题,可以用交叉熵做损失函数,找到分类器后,我们可以用它来计算距离,那么这样就涉及到了下面的等式:
\[\hat{d}_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T) =2(1-\min_{h\in\mathcal{H}}[\frac{1}{m}\sum_{\mathbf{x}:h(\mathbf{x})=0}\mathbf{I}[\mathbf{x}\in U_S]-\frac{1}{m}\sum_{\mathbf{x}:h(\mathbf{x})=1}\mathbf{I}[\mathbf{x}\in U_T]]) \tag{5}\]这里的证明不难,只需要注意
\[1=\frac{1}{2m}[\sum_{\mathbf{x}:h(\mathbf{x})=0}\mathbf{I}[\mathbf{x}\in U_S]+\sum_{\mathbf{x}:h(\mathbf{x})=1}\mathbf{I}[\mathbf{x}\in U_S]+\\ \sum_{\mathbf{x}:h(\mathbf{x})=0}\mathbf{I}[\mathbf{x}\in U_T]+\sum_{\mathbf{x}:h(\mathbf{x})=1}\mathbf{I}[\mathbf{x}\in U_T]\]同时注意到,需要的条件是$U_S,U_T$的采样数目相同,不然该等式是不成立的(实际使用的过程中,一般选择每个batch采样的数目相同)。根据等式$(5)$,我们可以通过交叉熵损失来训练分类器,然后拿最后得到的分类器来计算$h(\mathbf{x})$,从而计算$(5)$。一般而言,交叉熵损失越小,则说明$\hat{d}_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)$越小,说明两个数据集在整个假设空间(分类器空间)上的差距没那么大。
此外,还有一点我们需要考虑的,是用经验误差 $\hat{d}$ 来度量分布距离d所产生的偏差。这里我们不加证明地给出用\(d_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)\)来预测\(\hat{d}_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)\)的偏差。假设$\mathcal{H}$是所有基于从输入集 $\mathcal{X}$ 到标签集 ${0,1}$ 的分类器 $h$ 的假设空间,同时我们采用的分类器模型具有VC-dimension $d$,那么我们用采样数为m的经验距离\(\hat{d}_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)\)来估计\(d_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)\),这个估计的偏差满足,对于任意的 $\delta \in (0,1)$ ,以下Bound在至少$1-\delta$的概率下成立:
\[d_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)\leq \hat{d}_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)+4\sqrt{\frac{d\log(2m)+\log(\frac{2}{\delta})}{m}} \tag{6}\]关于VC-dimension,我们推荐这篇Tutorial。但是一般而言,在大部分文章中,等式$(6)$只是作为一个常规充门面的工作,而具体模型的VC-dimension也没什么特别大的作用,所以该Bound只是为了理论严谨性而提出的,实际Practice中没有那么有用。
通过构建Bound寻找Domain Adaptation的适用条件
我们在前面两节中先刻画了 $\epsilon_S(h),\epsilon_T(h)$ 的基本关系,定义了两个Domain的距离,对距离度量 \(d_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)\)给出了计算方法。在本节中,我们关心以下问题:首先,两个满足什么条件的域是可以进行域适应(Domain Adaptation)的呢?其次,如何利用可计算的距离\(d_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)\)来刻画 \(\epsilon_S(h)\)与\(\epsilon_T(h)\)的关系呢?
首先,我们引入一个定义,理想化联合假设(ideal joint hypothesis),它被定义为能最小化源域与目标域的联合预测错误的假设
\[h^*=\arg \min_{h\in \mathcal{H}}\epsilon_S(h)+\epsilon_T(h)\]同时,我们记在理想化联合假设 $h^*$的作用下,联合预测错误的值为
\[\lambda = \epsilon_S(h^*)+\epsilon_T(h^*)\]给定两个domain$<\mathcal{D}_S,f_S>$和$<\mathcal{D}_T,f_T>$,以及假设空间$\mathcal{H}$后,$\lambda$也被确定下来,它应该是一个常数。在我们期望能过进行域适应的任务上,这个常数应该总体而言”不会很大”,否则域适应的理论根本不能用。如果对假设空间的任何一个假设$h$而言,都没办法在两个Domain上得到不错的结果,那么整个问题就是不存在的(当然,这里要求是在两个Domain上得到不错的结果,Transfer Learning就放开了这一限制,我们可以先在$\epsilon_S(h)$上得到不错的结果,然后再在$\epsilon_T(h)$上进行微调。一般神经网络微调后,在原数据集上都会表现很差,这个叫做神经网络的灾难性遗忘问题)。
在域适应领域内,我们先假设$\lambda$是一个比较小的值,为了联系两个domain的误差关系,我们再给出一个定义,对称差异假设空间$\mathcal{H}\Delta\mathcal{H}$,这个定义是基于异或的思想,有点奇怪,但是我们之后就能看到它的威力
\[g\in \mathcal{H}\Delta\mathcal{H} \Leftrightarrow \exists h,h'\in \mathcal{H},g(\mathbf{x})= h(\mathbf{x}) \oplus h'(\mathbf{x})\]$\oplus$是异或操作,简单而言,对于任意$g\in \mathcal{H}\Delta\mathcal{H}$,它的映射结果都代表了都是原假设空间$\mathcal{H}$中两个假设的”不一致”。为什么要引入这种对称假设空间呢?因为我们需要刻画$h^*$与普通$h$的关系,并用$\lambda$作为一个上界。
下面,我们先用第一个不等式来揭示一下它的威力:对于任意两个假设$h,h’\in \mathcal{H}$, 我们有
\[\vert \epsilon_{S}(h,h')-\epsilon_{T}(h,h')\vert \leq \frac{1}{2}d_{\mathcal{H}\Delta\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T) \tag{7}\]证明:
\[d_{\mathcal{H}\Delta\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T) = 2\sup_{h,h'\in \mathcal{H}}\vert \mathbf{E}_{\mathcal{D}_S}\vert h(\mathbf{x})-h'(\mathbf{x})\vert- \mathbf{E}_{\mathcal{D}_T}\vert h(\mathbf{x})-h'(\mathbf{x})\vert \vert \\ =2\sup \vert\epsilon_{S}(h,h')-\epsilon_{T}(h,h')\vert\]同时,我们建立\(d_{\mathcal{H}\Delta\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)\)与\(d_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)\)的关系如下:
\[\frac{1}{2}d_{\mathcal{H}\Delta\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)\leq d_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)\]证明:先将数据集分块构建三个区间即可。对于任意一组假设\(h,h'\),我们记\(\mathcal{D}_{S_1}=\{\mathbf{x}\in \mathcal{D}_{S}:h(\mathbf{x})=1,h'(\mathbf{x})=0\}\),记\(\mathcal{D}_{S2}=\{\mathbf{x}\in \mathcal{D}_{S_2}:h'(\mathbf{x})=1,h(\mathbf{x})=0\}\),对于\(\mathcal{D}_{T}\)也同样划分为\(\mathcal{D}_{T_1},\mathcal{D}_{T_2}\),然后有
\[\frac{1}{2}d_{\mathcal{H}\Delta\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T) = \sup_{h,h'}\vert \mathbf{E}_{\mathcal{D}_S}\vert h-h'\vert -\mathbf{E}_{\mathcal{D}_T}\vert h-h'\vert\vert\\ =\sup_{h,h'}\vert\frac{\vert\mathcal{D}_{S_1}\vert}{\vert\mathcal{D}_{S}\vert}+\frac{\vert\mathcal{D}_{S_2}\vert}{\vert\mathcal{D}_{S}\vert}-\frac{\vert\mathcal{D}_{T_1}\vert}{\vert\mathcal{D}_{T}\vert}-\frac{\vert\mathcal{D}_{T_2}\vert}{\vert\mathcal{D}_{T}\vert}\vert\\ \leq \sup_{h,h'}\vert\frac{\vert\mathcal{D}_{S_1}\vert}{\vert\mathcal{D}_{S}\vert}-\frac{\vert\mathcal{D}_{T_1}\vert}{\vert\mathcal{D}_{T}\vert}\vert +\sup_{h,h'}\vert\frac{\vert\mathcal{D}_{S_2}\vert}{\vert\mathcal{D}_{S}\vert}-\frac{\vert\mathcal{D}_{T_2}\vert}{\vert\mathcal{D}_{T}\vert}\vert\\ \leq 2\sup_{h\in \mathcal{H}}\vert \mathbf{E}_{\mathcal{D}_S}\vert h\vert -\mathbf{E}_{\mathcal{D}_T}\vert h\vert\vert =d_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)\]因此,我们有以下的关系式
\[\epsilon_{T}(h)\leq \epsilon_{S}(h)+\lambda + d_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)\]证明:
\[\epsilon_{T}(h)\leq \epsilon_{T}(h^*)+\epsilon_{T}(h,h^*)\\ \leq \epsilon_{T}(h^*) + \epsilon_{S}(h,h^*) + \vert \epsilon_{S}(h,h^*) -\epsilon_{T}(h,h^*) \vert \\ \leq \epsilon_{T}(h^*) + \epsilon_{S}(h^*)+ \epsilon_{S}(h) + \frac{1}{2}d_{\mathcal{H}\Delta\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T) \\ \leq \epsilon_{S}(h)+\lambda + d_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)\]在实际计算中,我们往往优化的是$\hat{\epsilon}_{S}(h)$,并用上文所述的
\[\hat{d}_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)\]来进行距离估计。按VC-dimension理论,我们与$(6)$类似,不加证明地给出下面的不等式,即对于任意的 $\delta \in (0,1)$ ,如果给定的有标注的数据集采样为$m’$,以下Bound在至少$1-\delta$的概率下成立
\[\epsilon_{S}(h) \leq \hat{\epsilon}_{S}(h) +\sqrt{\frac{4}{m'}(d\log \frac{2em'}{d}+\log \frac{4}{\delta})} \tag{8}\]结合$(1)-(8)$,我们可以给出在几乎所有论文中都出现过的核心公式:
\[\epsilon_{T}(h)\leq \hat{\epsilon}_{S}(h)+\lambda + \hat{d}_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T) \\ +\sqrt{\frac{4}{m'}(d\log \frac{2em'}{d}+\log \frac{4}{\delta})} + 4\sqrt{\frac{d\log(2m)+\log(\frac{2}{\delta})}{m}} \tag{9}\]以后基本看到这个公式,就是这种算法。
从理论到实践:实际使用中work的三种域适应算法
特征对抗域适应:在特征空间上控制数据差异
从$(9)$中我们知道,对于在源域训练好的假设$h$,它在目标域的表现$\epsilon_{T}(h)$取决于
- 源域的验证表现$\hat{\epsilon}_{S}(h)$
- 假设空间的合理程度$\lambda$
- 域之间的距离$\hat{d}_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)$。
其中,假设空间$\mathcal{H}$一旦给定,$\lambda$就固定下来。那么,有没有办法让域之间的距离变得尽可能小呢?一个很自然的想法是通过特征空间过渡,如果我们设计两个映射,第一个映射将源域与目标域都映射到一个特征空间,在这个特征空间上,源域与目标域无法区分。然后我们再在特征空间上构造分类器,这样就能有效解决域适应问题。
与上文一致,我们同样对这个”特征空间”给出严格的数学定义。特征映射$r$是一个从输入空间$\mathcal{X}$到特征空间$\mathcal{Z}$的函数,给定一个模型,所有特征映射所组成的集合我们记作$\mathcal{R}$。此时,对一个给定域$<\mathcal{D},f>$假设$h$是一个从特征空间$\mathcal{Z}$到标签${0,1}$的映射,我们定义特征空间的标签函数$\tilde{f}$为
\[\tilde{f}(\mathbf{z})=\mathbf{E}_{\mathbf{x}\sim\mathcal{D},r(\mathbf{x})=\mathbf{z}}[f(\mathbf{x})]\]简单而言,对于一个给定特征$\mathbf{z}$,它的标签函数可以如下计算。我们找出分布为$\mathcal{D}$的输入空间上,所有映射到特征$\mathbf{z}$的点$\mathbf{x}$,再计算这些点的标签函数$f(\mathbf{x})$的期望即可。同样,对一个给定域$<\mathcal{D},f>$,我们定义特征空间上的分布函数为
\[\Pr_{\tilde{\mathcal{D}}}[B]=\Pr_{\mathcal{D}}[r^{-1}(B)],\forall B \subset \mathcal{Z}\]通过以上两个定义,我们就可以得到域适应的基本表示形式
\[\epsilon_{S}(h)=\mathbf{E}_{\mathbf{z}\sim \tilde{D}_{S}}\vert \tilde{f}(\mathbf{z})-h(\mathbf{z}) \vert;\\ d_{\mathcal{H}}(\tilde{D}_{S},\tilde{D}_{T})=2\sup_{h\in \mathcal{H}}\vert \Pr_{\tilde{D}_S}[I(h)] - \Pr_{\tilde{D}_T}[I(h)]\vert\]有了数学表达就给了我们用于水文章的很好理由,那么,具体实践过程中怎么用呢?一个最著名的方法是对抗域迁移模型,它的模型可以用一张图来解释
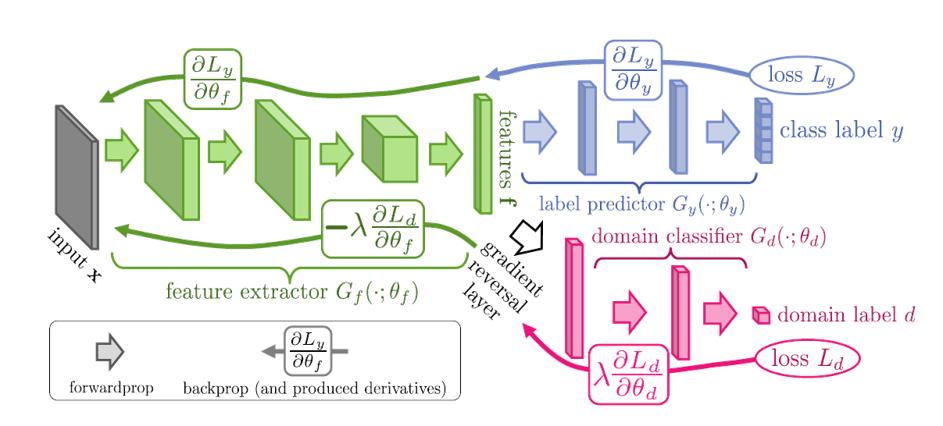
输入$x$后,模型先通过一个特征提取层(绿色)将输入映射到特征空间,得到特征。然后,模型将特征输入紫色的分类器,用于我们的目标任务分类,这一部分是用于训练模型的$\hat{\epsilon}_{S}(h)$。
此外,还有一个并行的红色结构,它也是一个分类器,只不过是用来区分输入的特征是属于源域还是属于目标域的,简单而言,红色的部分用于计算$\hat{d}_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)$。
在训练过程中,我们希望红色的分类器足够强,从而得到准确的$\hat{d}_{\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)$,同时又希望特征空间上源域特征与目标域特征尽量接近,从而混肴红色分类器,这就是一个对抗的思想。但是模型在训练过程中并没有采用对抗的思想,而是采用一种”逆梯度”(inverse gradient)的策略进行训练。简单而言,红色部分计算域分类损失,并用梯度下降法对参数进行更新。但是当该部分损失传到绿色的特征提取网络参数时,我们固定红色部分参数,用域分类损失所得到梯度的负数(inverse gradient)作为更新参数的梯度,目的在于增大域分类损失,混肴分类器。通过这样的训练过程,我们就能得到源域与目标域”差别不大”的特征空间了。
联邦特征域适应:多个Source Domain的联邦学习落地
联邦学习,即保护隐私的分布式学习方法,是一个很热的话题。在分布式学习任务中,我们往往会遇到多个源域的问题。比如,我们可以获取100个县的某个调研数据,但是这100个县的数据是分开存储的,彼此无法访问,同时有分布偏差,因此就组成了100个Source Domain,而我们只能通过联邦的方式对这100个Source Domain进行学习。同时,中心节点可以拿到很多无标签的数据,并希望模型在这些数据上得到很好的结果,这些数据组成了Target Domain,我们希望模型从Source domain 迁移到 Target Domain。对于这个问题,联邦域适应模型将联邦学习与对抗域适应联系在一起了。假如我们一共有$N$个域,对于某一个域$S_i$上训练的模型为$h_i$,那么对于任意域$S_i,i=1,\ldots, N$,仿照$(9)$式,我们都有 \(\epsilon_{T}(h_{i})\leq \hat{\epsilon}_{S_i}(h_i)+\lambda_i + \hat{d}_{\mathcal{H}}(\mathcal{D}_{S_i},\mathcal{D}_T)+C\) 如果我们把联邦学习得到的模型$h_T$看作是不同源域上训练的模型$h_i$的参数聚合,比如$h_T =\sum_{i=1}^{N}\alpha_ih_i$,那么我们可以得到联邦学习的特征域适应基本不等式 \(\epsilon_{T}(h_T)\leq \sum_{i=1}^N\alpha_{i}(\hat{\epsilon}_{S_i}(h_i)+\lambda_i + \hat{d}_{\mathcal{H}}(\mathcal{D}_{S_i},\mathcal{D}_T))+C\) 基于该数学表达,我们可以得到联邦域迁移的基本流程图
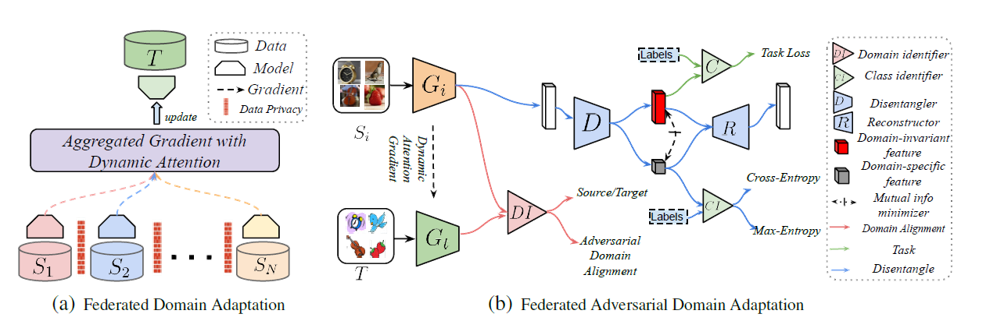
首先,对于每一个域,在联邦学习的框架下我们都能得到Target Domain以及该域对应的Source Domain数据,这样我们就可以用对抗域迁移的方法,对某个域训练特征提取器$G_i$,同时对抗训练分类器以最小化 \(\hat{d}_{\mathcal{H}}(\mathcal{D}_{S_i},\mathcal{D}_T))\) 在训练具体任务方面,注意到联邦学习框架下,Source Domain与Target Domain不再是一一对应的关系,而是一个典型的多对一的关系,因此在分类任务上,模型引入了常用的”域无关特征”与”对应域特征”,如图中的红色与灰色部分。为了将输入特征分离为域无关特征,减少域偏差对分类的影响,模型用了一个解纠缠器进行特征解耦,用得到的”域无关特征”用于完成目标任务,得到的”域相关特征”用于混肴目标任务,同时为了保证两个特征的独立性,我们通过最小化两个特征的互信息作为损失函数
其次,在联邦学习的过程中,如何从每个域的模型参数到联邦模型参数呢?这就是联邦学习里面如何加权平均的办法了。文中的思想很简单,如果我的Source Domain特征在与Target Domain特征进行对抗叠代的时候,Source Domain的特征对于目标的k分类任务而言变好了,那么这个Domain的权重就应该比较大,反之则小。在具体实践中,我们对第$S_i$个Domain的特征进行聚类,然后计算两次叠代前后该类的Info Gain,最后用所有Domain的Info Gain的softmax归一化进行评分(Note: 联邦学习的参数更新策略不是本文的重点,但是我觉得似乎有必要做一个综述)。
综合上述观点,文中的Federated Domain Adaptation的算法就自然给出了:

基于生成模型的域迁移:两阶段对抗训练
我们上文中提到,虽然现在我们说的域迁移模型往往是基于”对抗”的,但是实际上我们并没有用GAN的两阶段对抗网络进行,而是用了负梯度方法加以代替,这种方法的好处是可以”End-to-End”,但是却失去了GAN的二阶段对抗的神奇魔力。这里介绍最近比较著名的基于Cycle-GAN的域迁移模型:CYCADA。该模型用于分类任务,以及语义分割任务的域迁移中,基本框架如下:
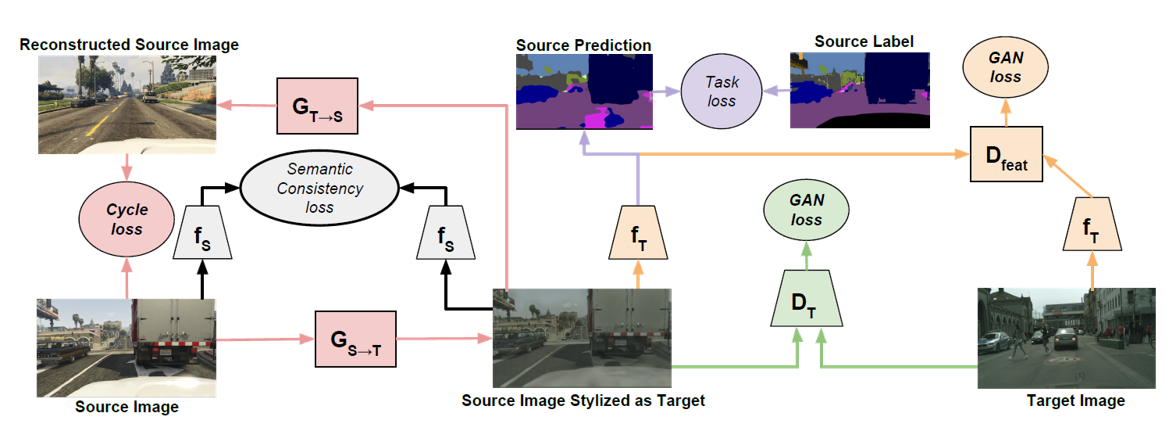
这个框架可以如下理解:首先,我们用GAN训练两个从Source Domain到Target Domain,再从Target Domain到Source Domain的生成模型$G_{S\rightarrow T},G_{T\rightarrow S}$。模型中的各个模块解释如下:
- 为了保证我训练的这个模型保留了图像的对应关系,我最小化输入图像经过循环生成前后的误差 \(\vert G_{T\rightarrow S}(G_{S\rightarrow T}(\mathbf{x}_S))-\mathbf{x}_S\vert \\ \vert G_{S\rightarrow T}(G_{T\rightarrow S}(\mathbf{x}_T))-\mathbf{x}_T\vert\)
- 为了保证我的模型在从Source Domain转化到Target Domain的过程中没有丢失分类语义信息,我需要最小化分类误差 \(CE(f_{S}(G_{S\rightarrow T}(\mathbf{x}_S)),label)\\ CE(f_{S}(G_{T\rightarrow S}(\mathbf{x}_T)),label)\)
- 为了保证我的模型在从Source Domain转化到Target Domain的过程中没有丢失语义分割信息,我需要最小化语义分割误差 \(Seg(f_{T}(G_{S\rightarrow T}(\mathbf{x}_S)),label_{S})\)
- 为了保证我们生成器$G_{S\rightarrow T}$得到目标域图像的语义分割结果与直接用目标域图像$\mathbf{x}_T$进行语义分割的结果也属于同一目标域,我们设计一个GAN,用语义分割结果作为输入,从而进行特征对齐 \(GAN(f_{T}(G_{S\rightarrow T}(\mathbf{x}_S)),f_{T}(\mathbf{x}_T)))\)
然后把这些loss加起来即可
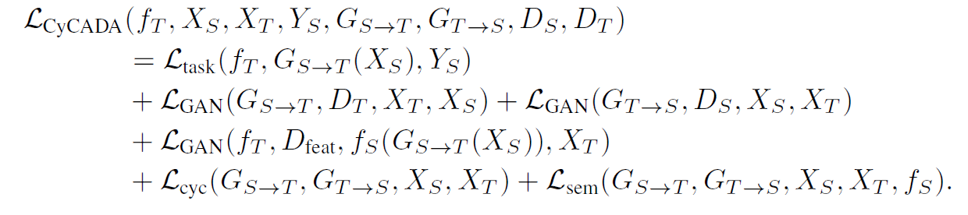
这个模型是纯视觉模型,没有什么严谨的数学,一切趋向于实用主义。
展望
本文主要梳理了域适应问题的基本知识,基础数学表达与实用的一些算法。接下来,我们希望能将变分自编码器的一些知识与域适应问题结合,从而得到更好的特征空间。同时,在代码方面,我们希望接下来能自己实现一些论文的算法,看看这个领域是算法奏效,还是trick奏效。此外,联邦域适应算法是一个比较能落地的东西,它的理论研究与更work的算法都是蓝海,非常值得水文章。