FengHZ‘s Blog首发原创
Introduction
We have introduced several classic VAEs in the previous 2 posts(A tutorial to VAE,Some notes on hierarchical VAE). The classical VAEs are all assumed to consist the following parts: an encoder which inference a posterior distribution $q(\mathbf{z}\vert \mathbf{x})$ of continuous latent random variables $\mathbf{z}$ given the input data $\mathbf{x}$, a prior distribution $p(\mathbf{z})$, and a decoder with a distribution $p(\mathbf{x}\vert \mathbf{z})$ over input data. Typically, the posteriors and priors of latent variable $\mathbf{z}$ in VAEs are assumed normally distributed with diagnoal covariance, which allows for the Gaussian reparametrisation trick to be used. However, a large number of datasets contain inherently discrete latent variables which can be difficult to capture with only continuous factors. In classification task for example, we aim to predict a discrete class label with multinomial distribution.
Here we introduce 2 VAEs proposed recently that can learn both continuous and discrete representations. The main references in this article are
Disentangled Joint Continuous and Discrete Representation
A natural way to combine discrete and continuous latent variables is to impose the conditionally independent assumption,and the posterior and prior distributions become
\[q_{\phi}(\mathbf{z},\mathbf{c} \vert \mathbf{x}) = q_{\phi}(\mathbf{z}\vert \mathbf{x})q_{\phi}(\mathbf{c}\vert \mathbf{x})\\ p(\mathbf{z},\mathbf{c}) = p(\mathbf{z})p(\mathbf{c})\]Under this assumption, the classical VAE objective
\[-E_{q_{\phi}(\mathbf{z},\mathbf{c} \vert \mathbf{x})}[\log p_{\theta}(\mathbf{x}\vert \mathbf{z},\mathbf{c})] + \mathcal{D}_{KL}[q_{\phi}(\mathbf{z},\mathbf{c} \vert \mathbf{x}) \Vert p(\mathbf{z},\mathbf{c})] \tag{1}\]can be written as a separated form of $\mathbf{z},\mathbf{c}$, and the loss becomes
\[-E_{ q_{\phi}(\mathbf{z}\vert \mathbf{x})}E_{ q_{\phi}(\mathbf{c}\vert \mathbf{x})}[\log p_{\theta}(\mathbf{x}\vert \mathbf{z},\mathbf{c})] + \mathcal{D}_{KL}[q_{\phi}(\mathbf{z}\vert \mathbf{x}) \Vert p(\mathbf{z})]+\mathcal{D}_{KL}[q_{\phi}(\mathbf{c} \vert \mathbf{x}) \Vert p(\mathbf{c})] \tag{2}\]Based on $(2)$, the paper mainly solves how to sample $\mathbf{c}$ from the discrete distribution $q_{\phi}(\mathbf{c}\vert \mathbf{x})$ and proposes a differentiable reparametrisation trick baed on the Gumbel Max trick. It also use information capacity method to provide an upper bound on the mutual information of
\[\mathcal{D}_{KL}[q_{\phi}(\mathbf{z},\mathbf{c} \vert \mathbf{x}) \Vert p(\mathbf{z},\mathbf{c})]\]which is proved to be the key to successfully train model.
Differentiable Reparametrisation Trick for Discrete Distribution
We naturally view $\mathbf{c}$ as discrete multinomial variable with posterior class probabilities $q_{\phi}(\mathbf{c}\vert \mathbf{x})=(\alpha_1,\ldots,\alpha_n)$, then we can sample $\mathbf{y}=(y_1,\ldots,y_k)$ from $q_{\phi}(\mathbf{c}\vert \mathbf{x})$ by sampling a set of $g_k \sim \text{Gumbel}(0,1) i.i.d$ and applying the following transformation
\[y_k = \frac{\exp(\frac{\log \alpha_k + g_k}{\gamma})}{\sum_{i} \exp(\frac{\log \alpha_i + g_i}{\gamma})}\]where $\gamma$ is a temperature parameter that controls the concentration level of the distribution. This transformation is inspired by latent variable formulation of the multinomial logit model, the model is
\[Pr(y=k) = \frac{\exp(\beta_k*x+\epsilon_k)}{\sum_{i}\exp(\beta_i*x+\epsilon_i)},\epsilon_i \sim \text{Gumbel}(0,1) \\ \log \alpha_i = \beta_i*x\]Information Capacity Method
The information capacity method are motivated by the following decomposition of the second and third term in $(2)$
\[E_{\hat{p}(x)}\mathcal{D}_{KL}[q_{\phi}(\mathbf{z}\vert \mathbf{x}) \Vert p(\mathbf{z})] = I_{q_{\phi}}(\mathbf{x};\mathbf{z}) + \mathcal{D}_{KL}[q_{\phi}(\mathbf{z})\Vert p(\mathbf{z})]\geq I_{q_{\phi}}(\mathbf{x};\mathbf{z}) \tag{3}\] \[E_{\hat{p}(x)}\mathcal{D}_{KL}[q_{\phi}(\mathbf{c} \vert \mathbf{x}) \Vert p(\mathbf{c})] = I_{q_{\phi}}(\mathbf{x};\mathbf{c}) + \mathcal{D}_{KL}[q_{\phi}(\mathbf{c})\Vert p(\mathbf{c})]\geq I_{q_{\phi}}(\mathbf{x};\mathbf{c}) \tag{4}\]It means when taken in expectation over the data, the KL divergence term is an upper bound on the mutual information between the latents and the data. The penalization on $(3)$ may lead the mutual information part to zero and make the latent variables failed to capture any representation of the input. To avoid this situation, the paper proposes an objective where the upper bound on the mutual information is controlled and gradually increased during training. We denote the controlled information capacity of continuous variable $\mathbf{z}$ and concrete variable $\mathbf{c}$ by $C_{\mathbf{z}}$ and $C_{\mathbf{c}}$, the final loss becomes
\[-E_{ q_{\phi}(\mathbf{z}\vert \mathbf{x})}E_{ q_{\phi}(\mathbf{c}\vert \mathbf{x})}[\log p_{\theta}(\mathbf{x}\vert \mathbf{z},\mathbf{c})] + \gamma \vert \mathcal{D}_{KL}[q_{\phi}(\mathbf{z}\vert \mathbf{x}) \Vert p(\mathbf{z})]-C_{\mathbf{z}}\vert + \\ \gamma \vert \mathcal{D}_{KL}[q_{\phi}(\mathbf{c} \vert \mathbf{x}) \Vert p(\mathbf{c})] -C_{\mathbf{c}} \vert \tag{5}\]Some Other Useful Tricks in Training Process
Hyperparameters
The JointVAE loss in equation $(5)$ depends on the hyperparameters $\gamma,C_{\mathbf{c}},C_{\mathbf{z}}$.
The value of $\gamma$ determines the balance between continuous and discrete latent variables. For a large combination of $\gamma$ in continuous part, the paper found the model either to ignore the discrete latent codes or to produce representations where continuous factors were encoded in the discrete latent variables.
The information capacity choice $C_{\mathbf{c}},C_{\mathbf{z}}$ should be considered carefully. If we assume the prior $p(\mathbf{c})$ obeys the uniform multinomial distribution with $p(\mathbf{c}=i)=\frac{1}{n}$, then we have the following inequation
\[\mathcal{D}_{KL}[p\Vert q]= \sum_{i}p_i \log \frac{p_i}{q_i}= -H(p)+\log(n)\leq \log(n)\]So during the training $C_c$ can be gradually increased to $\log(n)$.
The choice of $C_{\mathbf{z}}$ is much more complex and emperical. The author suggests to set $C_{\mathbf{z}}$ to be the largest value where the representation is still disentangled. We may also choose $C_{\mathbf{z}}$ as the peak point of $\mathcal{D}_{KL}[p\Vert q]$ during training.
The Analysis of Disentanglement
Disentangled representations are defined as ones where a change in a single unit of the representation leads to a change in single factor of varations of the input data while being invariant to other factors. Disentanglement is important in VAEs as we can assign different meanings to independent factors and use these factors to explain our model.
In general, the paper finds that it’s easy to achieve some degree of disentanglement for a large set of hyperparameters, but achieving complete clean disentanglement can be difficult.
The Choice of Discrete Dimensions
The dimensions of discrete variables highly depend on the dataset itself. If a discrete generative factor is not present or important, the framework may fail to learn meaningful discrete representations. In CelebA for example, it’s not clear what exactly would make up a discrete factor of variation. Actually, the specific dimension choice can be somewhat arbitrary: when using a 10 dimensional discrete latent variable, the model encodes 10 facial identities and when the dimension increases, it encodes more identities. It continuous until the dimension is larger than 100, and the model begins to encode continuous representations in the discrete variables. Similar situations also happen in MNIST dataset. When the discrete dimension is smaller than 10, it tends to confuse some digits such as 7 and 9. When using more than 10 dimensions, the model tends to separate different writing styles of digits into different dimensions.
VQ-VAE
Vector Quantization
Vector Quantization is one of the basic image compression technique. It focuses on the problem that how to compress a n-bits image to m-bits. Vector Quantization views the 3 channel $H\times W$ image as $H\times W$ 3-dim vectors and use k-means algorithms to cluster these vectors into m classes. Then we can map each pixel into the cluster label and compress the whole image into m-bits. We also need to create a dictionary recording the centroid of each cluster. When we want to unzip the compressed images, we just use the centroid of the corresponding cluster to fill each pixel. The detail of this algorithm can be found in this blog.
VQ-VAE
The paper “Neural Discrete Representation Learning” proposes VQ-VAE inspired by the vector quantization method. Actually I prefer to call it “VQ-AE” since it has little connection with variational inference and the distribution of latent variable is degenerate distribution.
The following figure describes the main structure of VQ-VAE
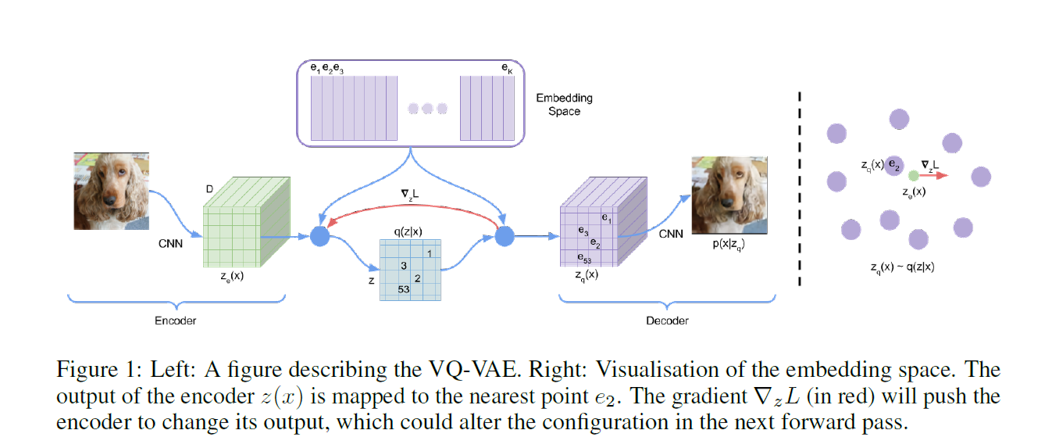
As seen on figure, it firstly defines a latent embedding space $\mathbf{e}\in R^{K\times D}$ where $K$ is the size of the discrete latent space and $D$ is the dimensionality of each latent embedding vector $\mathbf{e_i}$.The encoder takes a raw image $\mathbf{x}$ as input and output the concated feature $\mathbf{z_e(x)}$, then the discrete latent variables $\mathbf{z}$ are then calculated by a nearest neighbour look-up using the shared space $\mathbf{e}\in R^{K\times D}$. The input to the decoder is the corresponding embedding vector $\mathbf{z_q(x)}$ given as
\[\mathbf{z_q(x)_{i,j} = e_k},k=\arg\min _p \Vert \mathbf{z_e(x)_{i,j}-e_p} \Vert_2^2\]Since the embedding space $\mathbf{e}$ and the result of encoder $\mathbf{z_e(x)}$ is independent, we add the MSE loss inspired by k-means cluster progress to build the connection between $\mathbf{e}$ and $\mathbf{z_e(x)}$
\[L = \log p(\mathbf{x}\vert \mathbf{z_q(x)}) + \Vert sg[\mathbf{z_{e}(x)}]-\mathbf{z_{q}(x)} \Vert_2^2 \tag{6}\]The operation sg stands for stopgradient calculation. The optimization results of the second and third part in $(6)$ are
\[\mathbf{e_i = \sum _{n,i,j:\mathbf{z_q(x_n)_{i,j}=e_i}}}\mathbf{z_e(x_n)_{i,j}}/\vert \{n,i,j:\mathbf{z_q(x_n)_{i,j}=e_i}\}\vert\]which is the k-means centroid for the i-th cluster.
To give a brief summary, the VQ-VAE just utilizes the vector quantization method in the encoder feature and do the “feature compression” job instead of the fully connected feature encoder and decoder operation.